Sustainability
We have an important role to play in creating a more sustainable and inclusive future.

We have an important role to play in creating a more sustainable and inclusive future.

Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.

We put you first, so you can put our customers first.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.

Disclosures relating to our strategic, financial, operational, environmental and social performance.

See all the key dates in the financial year.

Higher, more sustainable returns as we continue to Help Britain Prosper.

With hubs across the UK, there's a place for you.

We're searching for the best talent to join us in Leeds.

Join us as we explore new ideas and technologies to reshape the world of finance.
We have an important role to play in creating a more sustainable and inclusive future.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.
We put you first, so you can put our customers first.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.
Disclosures relating to our strategic, financial, operational, environmental and social performance.
See all the key dates in the financial year.
Higher, more sustainable returns as we continue to Help Britain Prosper.
With hubs across the UK, there's a place for you.
We're searching for the best talent to join us in Leeds.
Join us as we explore new ideas and technologies to reshape the world of finance.
“The Responsible AI team is tasked with building algorithmic guardrails that can be used by our colleagues to ensure solutions remain compliant with the AI Assurance Framework – and can be trusted by the user.”

If you ask a trusted financial advisor a question like ‘which products should I invest in to reach my goal of putting down a deposit by 2028?’, you would hope that advisor would be competent in their area of expertise. You would also want them to be aware of general market trends, as well as UK specific regulations and context; be empathetic to your current life situation; and take all this into account to give you the most practical and honest roadmap of how to reach your financial goals.
Factualness, relevance, context specificity, empathy – these are the qualities that we value at Lloyds Banking Group when we are interacting with each other and our customers. They all feed into our values of Trust and being People First.
As the Group is undergoing the largest digital transformation in the UK financial sector, and we adopt more GenAI solutions, these values remain at the core of our practice. Articulating our values into practicable AI deployment standards is our AI Assurance Framework. To operationalise this framework in the form of technical tools, we have a dedicated team of data scientists and engineers embedded in the Lab enabling the building of GenAI solutions - making the build and deployment safe and secure for ourselves, our colleagues and for our customers.
The Responsible AI team at Lloyds Banking Group is tasked with building algorithmic guardrails that can be used by our colleagues developing GenAI solutions as part of their build, to ensure that these solutions remain compliant with the AI Assurance Framework – and therefore can be trusted by the user.
Guardrails allow for real time risk identification and quantification. They also allow the use case teams the ability to choose quantitative risk thresholds that are conformant with their own risk appetite. They have access to logs to monitor how the GenAI application is performing in production, and to make changes to the build if necessary.
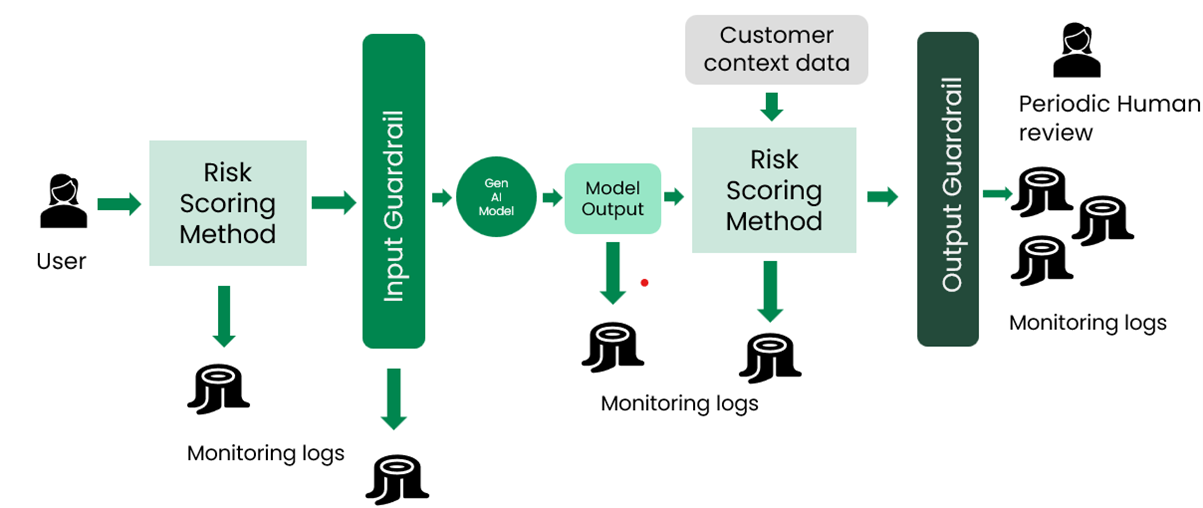
The risks that the guardrails functionality addresses are:
The risk identification and guardrail modules go hand in hand. The risk identification module calculates a score on the user input (for input guardrails) or the model output (for output guardrails), and the guardrail module validates this score against the user threshold. If the threshold is breached, a warning is raised. In either case, all messages raised are written in the logs to be monitored in future.
Our risk identification methods are broadly broken down into two types:
Machine learning based methods utilise more traditional methods used in Natural Language Processing (pre-GenAI) to calculate risk scores. One such example is cosine similarity. In this method, a vector space projection is taken of the piece of text to be scored vs a label that we want to test the similarity of that text to.
For example, a text sample maybe ‘Men are better at mathematics than women’ and the label might be ‘gender bias’. Using specific models that can ‘learn’ the context of a sentence, the cosine similarity method is able to return quite a high scoring indicating gender bias.
The positives of using these methods is that it is quite deterministic and explainable. This means that if the method is run on the same piece of text with the same label, we can expect to return the same cosine similarity score. As the input, output and method used to score is known – we can also easily point to the reasons why a particular score has been obtained.
We’re reimagining how we operate by harnessing the full potential of AI–embedding it across our business to drive smarter decisions, faster outcomes, and better experiences.
The downsides of using these methods are that they are very slow and cannot be used in GenAI applications which require low latency (such as a live chatbot) and they only work for very specific cases.
Last year, the Responsible AI team at Lloyds Banking Group was tasked with using this method on a use case that was trying to extract numbers from a set of documents without having to manually read them using GenAI; cosine similarity was quite bad at telling whether the numbers extracted by the GenAI model were correct or not.
The other set of methods that we use and call our Enterprise Guardrail are AI-Assisted. In this offering, we use a GenAI model as a judge to output a score based on the risk criteria on a certain model output. We instruct the model based on a risk prompt (that is customisable by users in case they don’t want to use our default one) that looks a bit like this:
The positive of using AI Assisted guardrails is that it is fast and we have managed to make them a lot faster through streaming contexts (for hallucination and misalignment). They are also really good at providing accurate results for a variety of use cases – which is not surprising as the main draw of GenAI models is their generalisability.
The major drawback of course is the probabilistic nature of the GenAI model itself. This means that the scores obtained for the same run are not always the same – lack of exact reproducibility. The model is also less easy to explain. To assuage the issues of reproducibility, we have decided to use a binary flag of pass or fail for some of our users.
Sometimes we are asked if it is a bit suspect to have a GenAI model assess the outputs of a GenAI model. The answer is both yes and no. A GenAI model assessing itself is a bit of a misconception. A GenAI model is not a sentient being (despite what the news might try to tell you), and therefore having a model assess the outputs of another instance of the same model is not the same as a human being marking their own homework.
There are limitations of this, of course, as the training data is the same as it is obviously the same model. Bypassing this by using a different Large Language Model is not as productive as the training data is largely the same for most proprietary Large Language Models (GenAI models is used synonymously in this case). This consideration is vastly different of course, as we are now moving towards using context specific Small Language Models as judges. We believe that this is the future of GenAI guardrails, as demands on context specificity, lower latency and lower computational cost grow.
Rohit Dhawan believes that AI will revolutionise the financial services industry over the coming decade. And the transformation will be broad – impacting everything from customer experience to administrative operations.
The Responsible AI team at Lloyds Banking Group was ultimately born in the organisation by the bringing together of a group of concerned Responsible AI practitioners and Data Scientists. Keeping us all safe and unlocking the benefits of AI for more of us, rather than a few, is a collaborative effort.
We have decided to start a small experiment in our organisation around the building of guardrails by starting an inner source ‘contribution guardrail’ project. If anyone in the Group builds a guardrail, we provide them a standard template of how to do it, but then they can contribute to this shared resource.
We approve the builds that go in, and we have contributed some ourselves. To encourage a bit of healthy competition, we also have an evaluation framework and a leaderboard to see which implementations perform better than others.
Riding the GenAI wave is exciting. The Responsible AI team is here to make sure Lloyds Banking Group rides this wave safely, with the right gear, and a surfboard that can deal with a rough sea!
Tech Lead for the Responsible Gen AI Team
Chandrima is the Tech Lead for the Responsible Gen AI Team at Lloyds Banking Group. The vision they drive in their work is to make AI and technology accessible and democratic for many rather than a few. They are an erstwhile physicist - when not fiddling with the newest Language Model, they are an avid cook, and an untiring seeker of a good conversation.
Through more than £3 billion investment into our people, technology and data, we’re enhancing our resilience and security against cyber threats, simplifying our architecture and putting cloud technology at the heart of everything we do.
Build something that changes everything. Join us as we explore new ideas and technologies to reshape the world of finance.
With its ability to process vast datasets, identify patterns and make real-time decisions, AI is enabling fintechs to deliver smarter, faster, and more personalised services than ever before.
Generative AI & Agentic AI success hinges on having the right model for the job, context engineering that feeds foundation models the right materials to reason, and evaluation to understand how well a model performs on specific task.
Popular topics you might be interested in