Sustainability
We have an important role to play in creating a more sustainable and inclusive future.

We have an important role to play in creating a more sustainable and inclusive future.

Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.

We put you first, so you can put our customers first.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.

Disclosures relating to our strategic, financial, operational, environmental and social performance.

See all the key dates in the financial year.

Higher, more sustainable returns as we continue to Help Britain Prosper.

With hubs across the UK, there's a place for you.

We're searching for the best talent to join us in Leeds.

Join us as we explore new ideas and technologies to reshape the world of finance.
We have an important role to play in creating a more sustainable and inclusive future.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.
We put you first, so you can put our customers first.
Our report provides an update on how we are Helping Britain Prosper in a way that delivers long-term profit and returns.
Disclosures relating to our strategic, financial, operational, environmental and social performance.
See all the key dates in the financial year.
Higher, more sustainable returns as we continue to Help Britain Prosper.
With hubs across the UK, there's a place for you.
We're searching for the best talent to join us in Leeds.
Join us as we explore new ideas and technologies to reshape the world of finance.
Text-to-SQL (Structured Query Language) is a technology that enables users to query relational databases using natural language instead of traditional SQL syntax. It leverages Natural Language Processing (NLP) and Large Language Models (LLMs) to translate human-readable questions into structured SQL queries.
This approach is particularly valuable in large organisations, where empowering non-technical users to access data directly can reduce bottlenecks, improve agility, and support data-driven decision making.
Over the past year, Lloyds Banking Group has made significant strides towards this vision. This article highlights the key technical achievements and milestones shaping the future of data interaction at the Group.
The concept isn’t new; systems like LUNAR1 and CHAT-802 explored natural language interfaces in the 70s and 80s, validating the need for intuitive data access. However, rule-based methods and compute constraints limited its scalability. Today, advances in LLMs, schema-aware encoding, and prompt engineering bring us closer than ever to accurately generating SQL across diverse domains.
Almost two years ago we had a vision of improving our engineering efficiency and speeding up delivery cycles. We also wanted to democratise access to data and insights, through an intuitive tool that eliminates technical barriers and unlocks greater value from our data assets.
We’re using the power of tech and data to offer our customers hyper-personalised services and seamless experiences on their device and channel of choice.
Dialogue with Data (DwD) is Lloyds Banking Group’s experiment to explore text-to-SQL using GenAI technology, introducing Agentic concepts. It was developed and tested in our “Innovation Sandbox” using Google Cloud Platform (GCP) environment isolated from production. This provided safe conditions, access to the latest models and scalable compute for rapid, iterative learnings.
Through our experimentation framework, we selected a low risk, yet high‑value Business Intelligence (BI) use case, using a synthetically generated Human Resource (HR) dataset that mirrors holiday and training records. This enabled us to validate end‑to‑end Text‑to‑SQL workflows (governance, guardrails, and UX) without exposing sensitive data.
The experiment was divided into three phases:
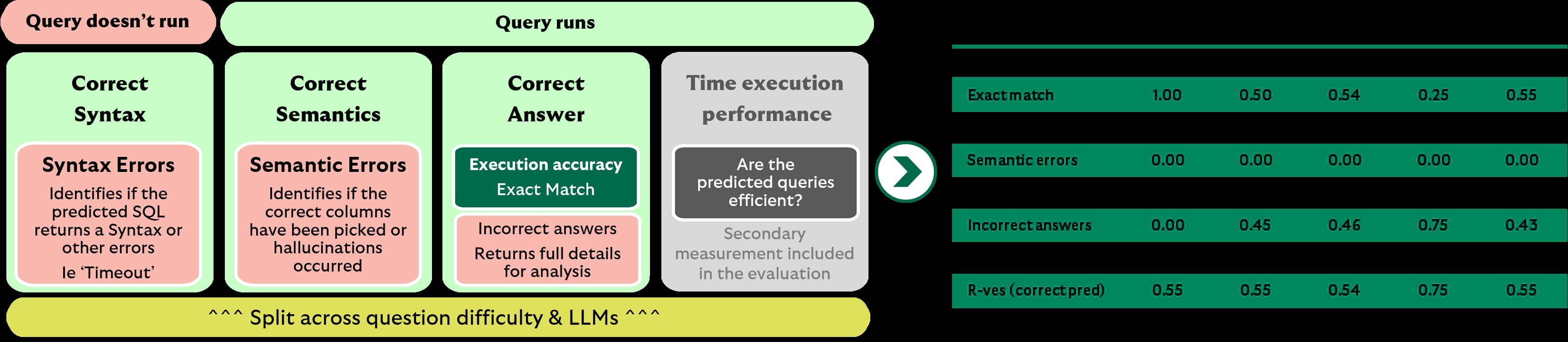
Phase one benchmarked LLMs on their ability to generate accurate SQL from natural language prompts. The experiment surfaced limitations in off-the-shelf evaluation tools like Spider and Bird, prompting the creation of a bespoke Group-specific automated evaluation pipeline. The resulting framework supports nuanced assessment, including human-in-the-loop review, and laid the foundations for future phases.
Phase one labelled ‘zero shot’ (see Figure 1). We provided the full schema the above instruction prompt (see Figure 2) and iterated through a set of 44 questions curated from seven business users ranging in difficulty from easy to extra hard.
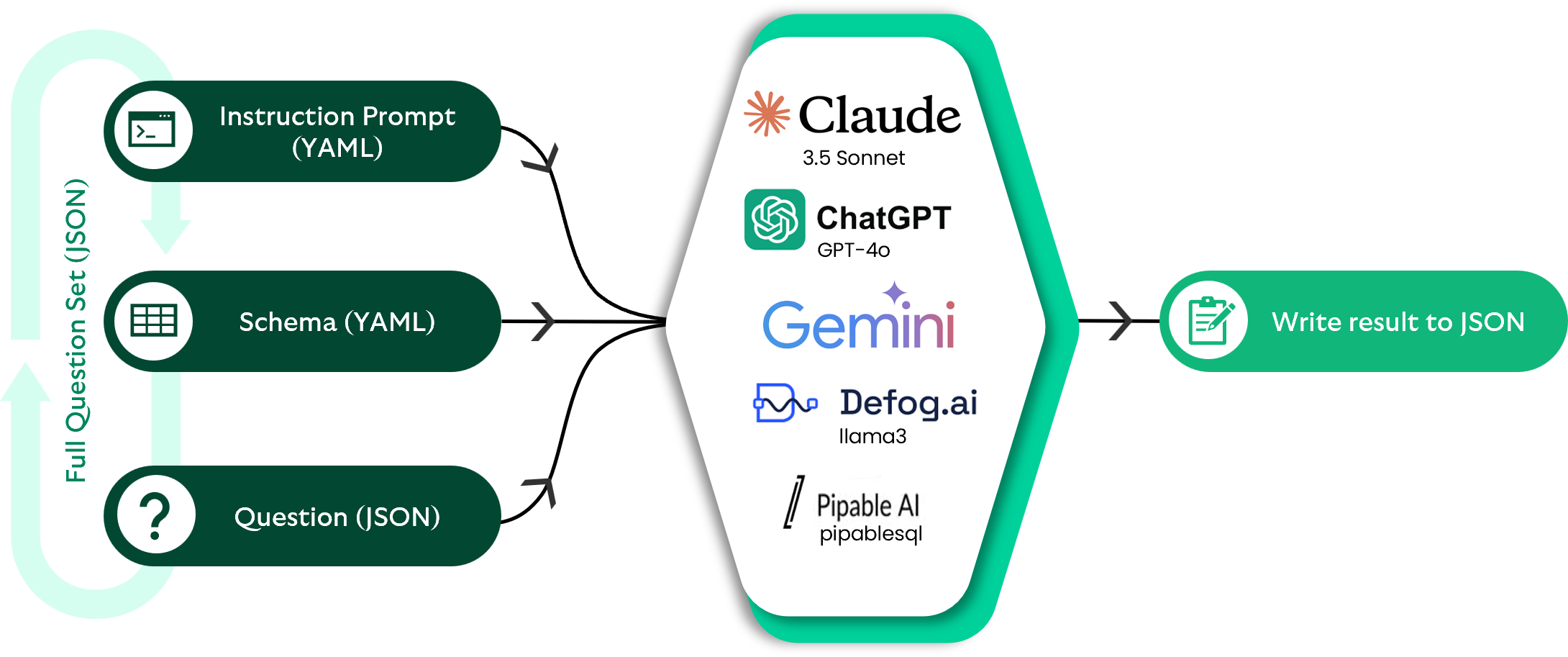

Code snippet template for generating SQL statements based on a database schema and user question. Includes placeholders for schema, table creation statements, and user input, with instructions to ensure proper SQL syntax and formatting.
To ensure deterministic behaviour and reproducibility across model evaluations through all phases; all sampling related parameters including temperature3, top-p4 and top-k5 were fixed at zero or their lowest permissible values. This attempted to suppress the inherent stochasticity of LLMs, enabling as consistent output generation as possible across repeated runs and helped in facilitating fair comparative analysis.
The automated evaluation pipeline included metrics such as execution accuracy, syntax and semantic correctness, and time-based scoring (R-Ves6). Additional metrics like Soft-F17 were used to account for minor variations in output structure, further strengthening the robustness of the analysis.
Whilst the automated evaluation pipeline performed well, it became clear that human evaluators played a crucial role. Programmatic metrics such as soft F1, Exact Match (EM), and accuracy do not always fully capture correctness. In practice, evaluation often required resolving ambiguity in cases where multiple permutations of valid SQL statements could be considered correct. Human evaluators were also essential in judging partial correctness, ensuring that results aligned with the intended meaning of the input query.
The evaluation revealed that while state of the art (SoA) models such as Claude 3.5 Sonnet, GPT 4.0 and Gemini demonstrated strong performance on objective queries, particularly in the "easy" and "medium" categories, they struggled with more subjective or domain-specific questions. This insight was reinforced through targeted human evaluation, which underscored the importance of schema context and the injection of domain knowledge.
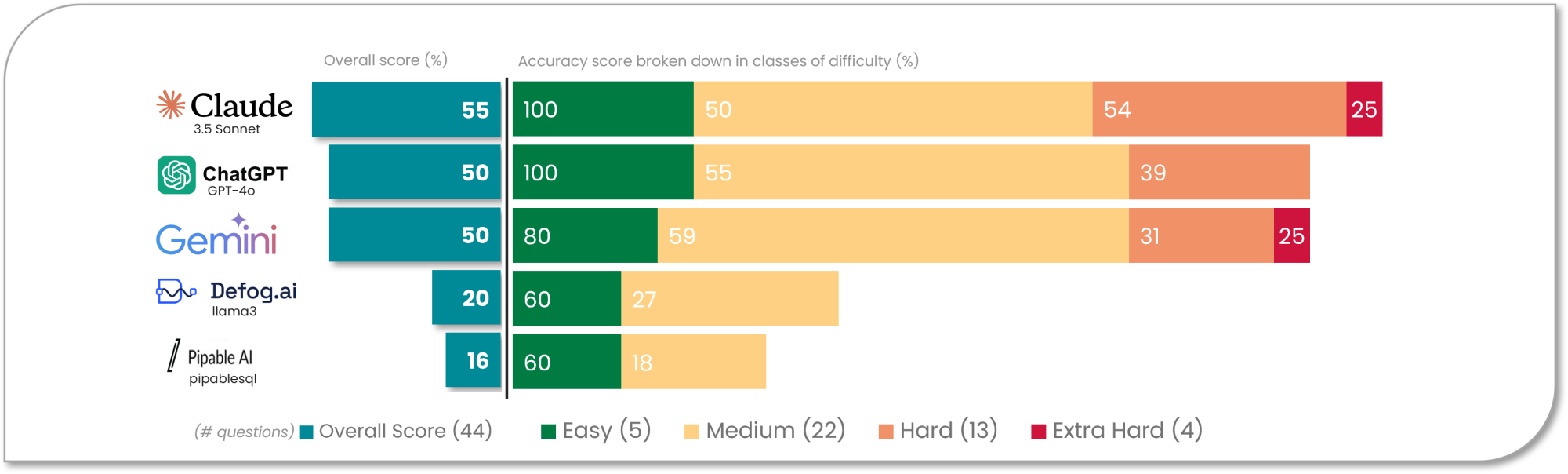
Notably, specialised text-to-SQL open-source models such as Defog.ai and PipableSQL exhibited significantly lower accuracy across all difficulty levels, highlighting a clear performance gap between SoA and open-source alternatives.
Another divergence between experimental setups and real-world deployment is the impact of differing Data Definition Language (DDL) environments on performance metrics. Initially, we aligned with open-source frameworks used by Spider and Bird, which at the time relied on SQLite. This consistency supported the development of our own automated evaluation pipeline. However, deploying SQLite in a production grade enterprise environment proved more complex, prompting a transition to PostgreSQL as an interim step.
Following the PostgreSQL migration, model performance degraded. We attribute this, in part, to dialect bias driven by SQLite’s simpler SQL and its prevalence in benchmark datasets, which nudges models toward SQLite syntax. To enable migration from the Sandbox to other environments and improve scalability, we made the decision to transition to Google Gemini paired with BigQuery.
To bring the experiment to life and enable user experience testing, we developed a working MVP (Minimum Viable Product) that served as both a functional prototype and a demonstration tool. This allowed us not only to showcase the potential of conversational analytics in a live environment, but also to validate integration pathways, assess usability and gather early feedback to inform future iterations.
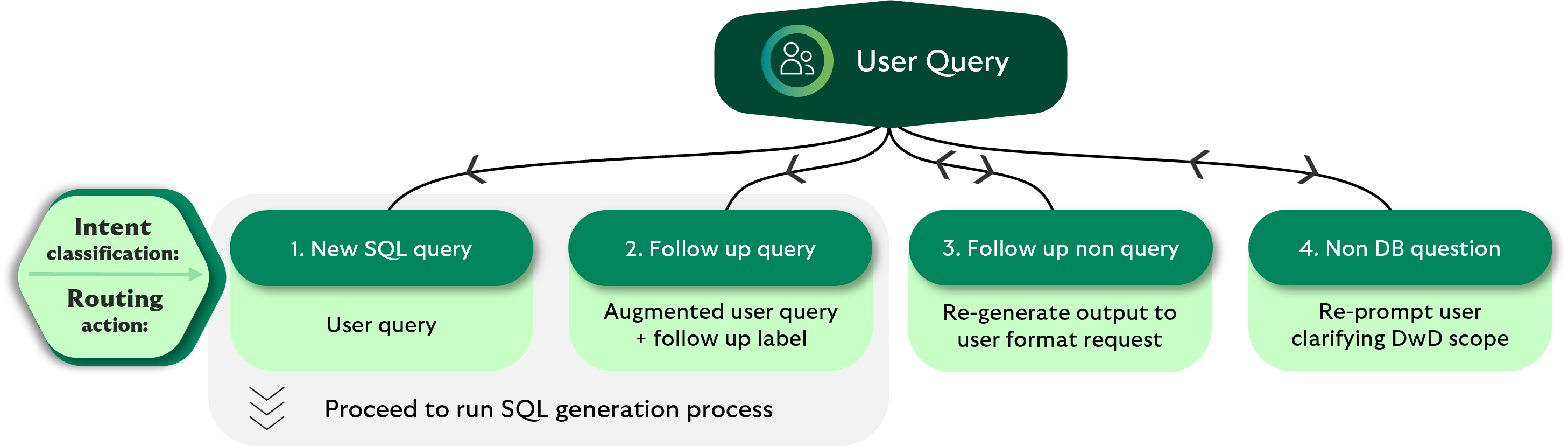
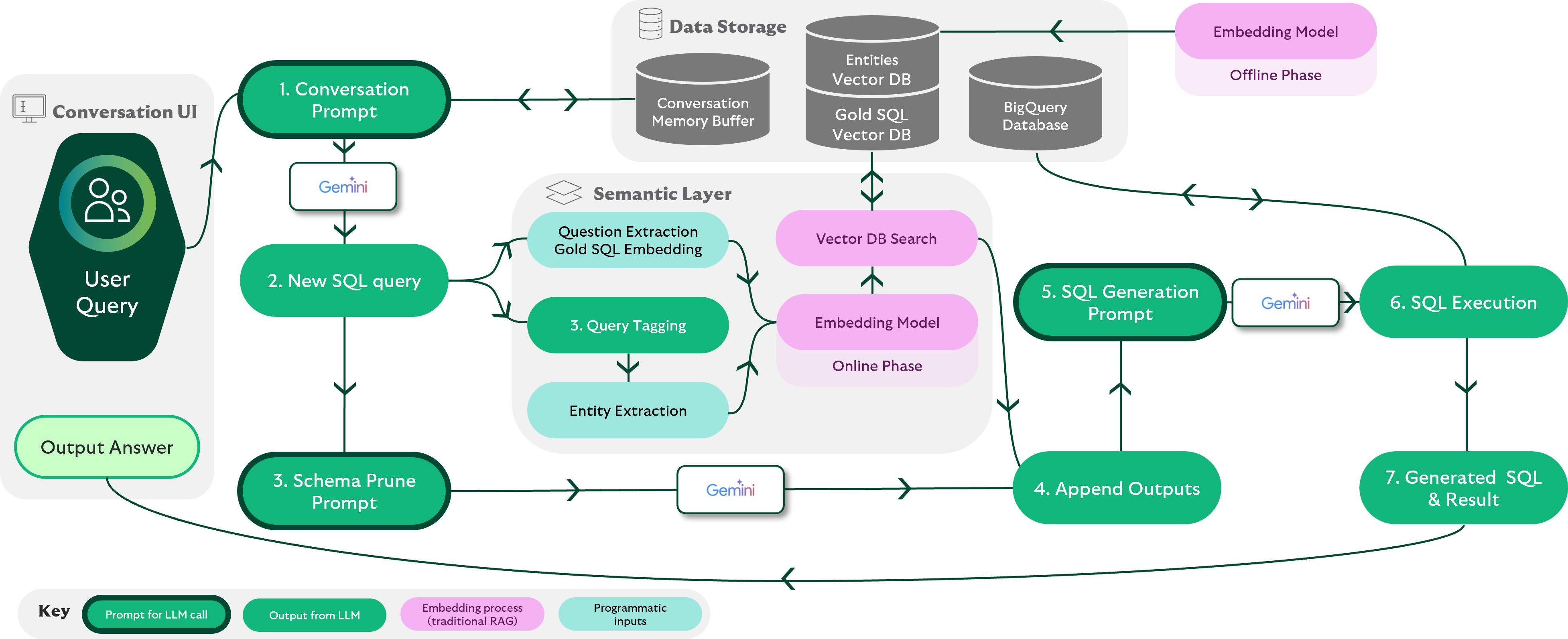
We manage conversations using a simple memory buffer, as we currently have no prior user history. At this stage, we’ve adopted a straightforward approach by leveraging Gemini Flash 1.5 to handle user intent (see conversation management figure):
While the conversation management handles structured exchanges effectively and is simple to implement, it doesn’t yet account for the probabilistic and context-sensitive nature of real human conversation. Future iterations will need to incorporate more sophisticated intent modelling and contextual memory to manage conversational permutations.
As part of the early experiment, we looked at how to improve the SQL generation component in isolation. For this we were still ingesting the schema within a system prompt but in some scenarios, it would have been disseminated in separate LLM calls.
Despite progress, accuracy consistently hit an 80% EM ceiling due to limitations in semantic understanding. To address the underlying challenge, we introduced two critical enablers, robust schema management and a semantic layer, resulting in an EM score of 86.1% on a validation set collated from different business users.
What began as a traditional DDL schema with basic descriptions has evolved to include synonyms/acronyms and nominal distinct column values to enrich semantic understanding.

We began by compiling the schema into CSV and splitting it across the stages ready for our Retrieval-Augmented Generation (RAG) workflows. For schema pruning, we deliberately eschewed RAG and used the LLM in parametric (closed-book) mode to condense field descriptions, remove redundancy, and prioritise high-utility columns. This semantics-aware pass was more effective than keyword-driven pruning.
For mapping domain context language to the schema, we relied on traditional Name Entity Recognition (NER)/tagging rather than the LLM. A rules and dictionary based NER layer handles discreate nominal columns8, synonyms, and acronyms, and resolves hierarchies that span multiple columns (e.g., Layer_1 … Layer_x). This made it straightforward to assert, for example, that “Department A” belongs to Layer_3 hierarchies and to provide that context to the generation phase coupled with the pruned schema as a first pass.
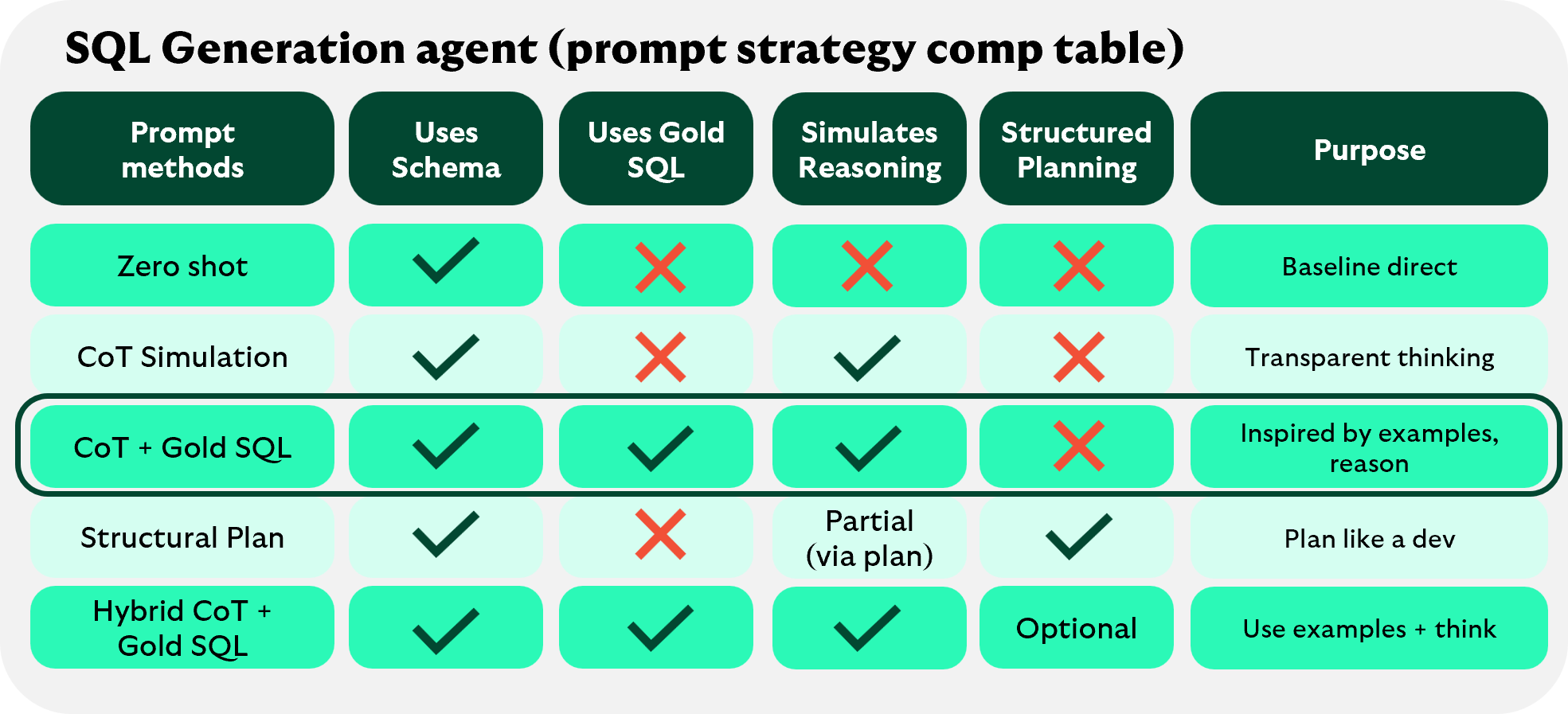
We also incorporated Gold SQL into the RAG pipeline. Using a single-prompt strategy with structured CoT and Gold SQL exemplars, we observed strong gains in both accuracy and latency. Additionally, when a user request is a 1:1 match to a previously validated query, we can bypass generation and return the stored Gold validated SQL.
The way the schema and semantic layer are consumed is arguably the most critical factor in designing a robust text-to-SQL system. This becomes even more important when working with large schemas, though even with relatively small schema, we observed auto-regressive9 bias during rapid prototyping particularly when the schema was embedded directly within the SQL generation prompt.
The performance of text-to-SQL in a real-world setting, is significantly different to that in existing benchmarks especially when faced with nuanced domain specific context.
Accuracy is often perceived as an absolute measure, yet in practice, it is far from straightforward. While creating a benchmark dataset provides a controlled environment for evaluation, real-world conditions introduce noise, ambiguity, and variability that benchmarks rarely capture.
A key challenge lies in defining ‘ground truth’. Labels are typically treated as objective, but they are created by humans bringing inherent subjectivity and bias. This raises an important question: can we ever claim 100% accuracy when the very notion of correctness depends on human interpretation?
These factors create a persistent gap between model performance in benchmark settings and operational environments. Recognising this gap is critical for designing robust systems and setting realistic expectations for stakeholders.
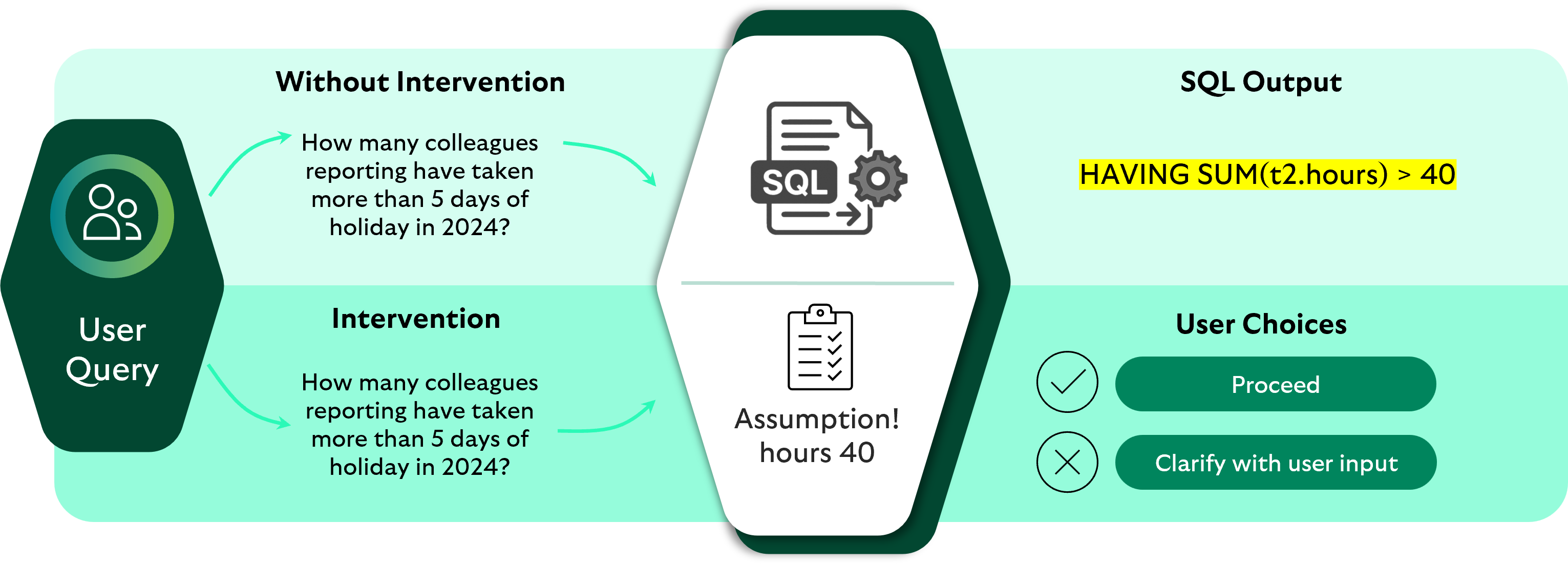
Data democratisation is still the right ambition, but it remains elusive for a system to truly handle ambiguous questions which often come in the form of true natural language, ie “How well are we doing?” These questions today sit outside of any descriptive dashboard that even a semantic layer will not be able to solve.
We believe the focus should be on enabling a human-in-the-loop system that learns from user experience, with transparency for users at its core.
We developed DwD with a small team of highly skilled engineers. What began as a text-to-SQL experiment has evolved into a broader industry concept now recognised as Generative Business Intelligence (GenBI). Building on the internal success of DwD, we are now working closely with our strategic partners and wider teams to explore how these learnings can be implemented and deliver value across the bank.
Our ambition is to offer conversational data access as a reusable, cross-domain service enabling more intuitive, efficient and secure engagement with data across Lloyds Banking Group.

Lead Data & AI Scientist
Matthew Mason is a Lead Data & AI Scientist in Lloyds Banking Group’s Chief Operating Office. He leads the development and deployment of innovative solutions that enhance operational efficiency across the organisation.
Prior to his current role, Matthew held a range of positions in engineering, analytics, and data science within the Group. His career began in the branch network over 16 years ago, marking the start of a journey that has evolved into a deep focus on data and technology.

Senior Enterprise Architect
Azahar is a subject matter expert in AI. An Enterprise Architect, with a focus on emerging trends in AI. Innovation and experimentation with emerging tech is a critical part of his life.
He has worked with startups and FTSE 100 companies delivering solutions based on technologies such as Conversational AI, 5G, and Cloud. He has a Ph.D. in Artificial Intelligence looking at generative design.

Innovation Experiment Lead
Ansel Liu is an Emerging Technology and Innovation Manager in the Chief Technology Office (CTO) at Lloyds Banking Group. He leads initiatives to assess the impact of emerging technologies on colleagues, customers, and clients, and drives experimentation to unlock new customer segments and business models.
Over the past four years, Ansel has focused on developing technology-led propositions and running experiments in areas (such as BNPL, Data Product and GenAI, with an emphasis on business and commercial banking use cases.
Prior to Lloyds Banking Group, Ansel worked in tech strategy consulting, corporate venture building and co-founded NOMAD, a PropTech startup within the LabTech Group.
27 Aug 2025 | Duncan Kirkpatrick
Lloyds Banking Group is transforming the insurance experience through digital tools like five-minute claims processing and self-service policy management, while maintaining human support for complex cases.
249 August 2025 | Rohit Dhawan
Lloyds Banking Group’s responsible AI framework ensures rigorous testing, human oversight, and scenario planning to prevent harm, with real-world safeguards like escalation protocols for virtual assistants and fraud detection systems.
18 August 2025 | Rob Hale and Peter Left
By embracing digital assets, smart contracts, and DLT, we’re not just improving existing processes – we’re reimagining what’s possible.
Popular topics you might be interested in